事件循环
process是计算机执行的最小实例。一个process可以有多个threads,OS调度负责线程和进程的资源分配。
什么是事件循环?
事件循环是Event-Driven Architecture的一种实现机制。EDA广泛应用于各种服务中,比如GUI编程、Redis、Nginx等.
事件循环通常包含三个部分:Event Loop、Event Queue、Event Handler.
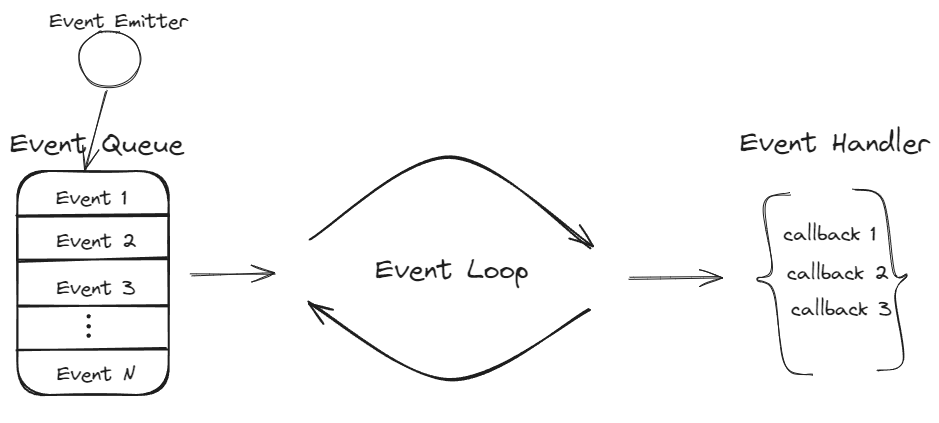
开启一个线程,初始化Event loop,从事件队列中取出事件,执行相应的回调函数,事件触发器不断产生不同的事件,加入事件队列,然后事件循环取出事件,执行相应的回调函数;再取下一个事件,不断重复此过程。
NodeJS中的事件循环
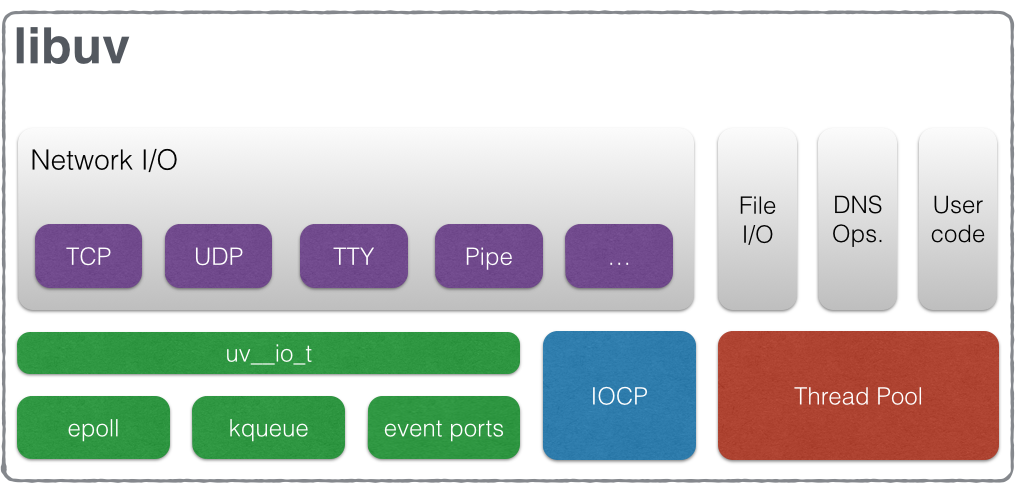
NodeJS中的事件循环是 libuv 库实现的。[libuv](libuv documentation)是一个跨平台的异步I/O库,它提供了事件循环。
Full-featured event loop backed by epoll, kqueue, IOCP, event ports.
什么是事件循环?
尽管JavaScript是单线程的,事件循环通过尽可能将操作转移到系统内核中。允许Node.js执行非阻塞I/O操作。
因为现代大多数的内核是多线程的,它们可以处理在后台执行的多个操作。当某个操作完成时,内核告诉Node.js,将合适的回调加入到poll队列,最终被执行。后面我们会详细解释。
Event Loop解释
当Node.js启动时,初始化事件循环,处理输入的代码(或者丢入REPL),代码中可能有异步的API调用,计时器,或者process.nextTick(),然后开始处理事件循环。
下图展示了一个事件循环大概的操作顺序:
1 | ┌───────────────────────────┐ |
每个框框都是事件循环的一个“阶段”。
每个阶段都有一个要执行的回调函数的FIFO队列。每个阶段都是独特的。一般情况下,当事件循环进入到指定阶段,它会执行该阶段特定的操作,然后执行该阶段队列中的回调,直到队列为空或达到最大回调执行限制。之后,事件循环会进入下一阶段。
因为这些操作可能会调度另外的操作,所以轮询(poll)阶段处理的新事件会由内核入队,处理轮询事件时,可能会有新的轮询事件入队。长时(long running)回调使得轮询阶段运行的时间远超定时器的阈值。后面的定时器和轮询部分会详细介绍。
在实现上,Windows和Unix/Linux有点不同,对于解释来说不重要。最重要的部分是,实际上有7到8步,但是我们关注的是Node.js使用的、上面说的几步。
阶段概览
定时器:执行
setTimeout()和setInterval()的回调pending 回调:执行移交给下一循环的I/O回调
idle,prepare:内部使用
poll:获取新的I/O事件;执行I/O相关的回调(几乎所有的回调,除了close事件的回调,定时器回调,和
setImmediate);node会适时的阻塞check:
setImmediate()回调执行close回调:一些’close’事件的回调,比如:
socket.on('close', ..)
在每次事件循环运行中,Node.js检查是否在等待任意异步I/O或定时器,如果没有就关掉。
阶段详情
定时器
定时器指定了一个阈值,在多少毫秒之后可以执行回调,而不是期望执行的确切时间。在指定时间之后,定时器的回调函数会尽早调用,但是,操作系统调度或者其他回调函数的执行可能使它们延迟。
技术上,poll阶段控制了定时器何时执行。
比如,你调度了一个100ms后执行的回调,然后你的脚本开始异步读取一个文件,花了95ms:
1 | const fs = require('fs'); |
当事件循环进入poll阶段,该阶段有一个空的队列(fs.readFile() 还没有完成),所以还要等几毫秒,直到最近的定时器阈值到了。当在等待95ms时,fs.readFile() 完成了文件读取,它的回调(10ms)加入到poll队列,然后执行。当回调完成后,队列中没有了回调,所以事件循环会看看:最近的定时器阈值到了,然后回到定时器阶段,执行定时器的回调函数。在这个例子中,你会看到,定时器定都和它的回调执行之间的延迟是105ms.
为了防止poll阶段阻塞事件循环,libuv(实现了Node.js事件循环和所有异步行为的C语言库)有硬编码的最大事件限制(依赖于系统)。
挂起回调(pending callbacks)
这个阶段执行一些系统操作的回调,比如TCP错误。举个例子,如果一个TCP socket尝试连接时接收到了ECONNREFUSED,一些unix系统要等待来报告错误。这就会加入到队列中,在挂起回调 阶段执行。
轮询(poll)
轮询阶段有两个主要的功能:
计算阻塞和I/O轮询要花费多长时间,然后
处理轮询队列中的事件
当事件循环进入到轮询阶段,没有计时器调度时,会有下面两种情况:
如果轮询队列不为空,事件循环将同步执行队列中的回调函数,直到队列中所有回调处理完或者达到最大回调数量限制。
如果轮询队列为空,又有下面两种情况:
如果脚本由
setImmediate()调度,事件循环就会结束poll阶段,进入check阶段,执行这些调度的脚本。如果没有被
setImmediate()调度,事件循环就等待回调函数加入到队列中,然后立即执行。
一旦poll队列空了,事件循环就检查定时器,看看哪一个阈值到了。如果一个或者多个定时器就绪,事件循环就回到定时器阶段,执行那些定时器回调函数。
check
这个阶段允许用户在poll阶段完成之后立即执行回调。如果poll阶段空闲了,脚本就入队到setImmediate(),事件循环可能进入check阶段,而不是等待。
setImmediate()实际上是一个特殊的定时器,运行在事件循环的独立阶段。它使用了libuv API,该API调度在poll完成后执行的回调。
一般来说,代码执行,事件循环最终会到poll阶段,等待下一个连接、请求,等等。但是,如果回调由setImmediate()调度了,poll阶段就会空闲,那就会结束然后进入check阶段,而不是等待poll事件。
close回调
如果一个socket或者handle突然关闭(比如,socket.destroy()),'close' 事件就会在这个阶段触发。否则就会由process.nextTick() 触发。
setImmediate() VS setTimeout()
setImmediate() 和 setTimeout()很相似,但是根据他们调用的时机,表现出来的不一样。
setImmediate()的设计是,一旦当前的poll 阶段完成了,就执行脚本setTimeout()是在最小timeout时间达到后,执行脚本。
定时器执行的顺序会取决于调用的上下文。如果两个都在main模块中调用,那就受进程的性能限制(被机器上其他运行的应用影响)。
比如,如果我们执行下面的脚本,该脚本不在一个I/O循环内(比如,main模块),两个定时器的执行顺序就不确定,因为被进程的性能限制:
1 | // timeout vs immediate.js |
1 | node timeout_vs_immediate.js |
但是,如果你把两个调用移到一个I/O循环内,immediate回调就会先执行:
1 | const fs = require('fs'); |
使用setImmediate() 的主要优势是,在一个I/O循环内,无论有多少定时器,它的执行顺序总是优先于任何定时器。
理解process.nextTick()
你可能注意到了,process.nextTick()没有出现在流程图中,虽然它是异步API的一部分。这是因为process.nextTick()技术上不是事件循环的一部分。相反,nextTickQueue会在当前操作完成后处理,无论事件循环当前是在哪个阶段。在这里,一个操作是指从底层C/C++ handler的转换,以及处理要执行的JavaScript.
再看我们的流程图,在指定阶段,任何时候你调用process.nextTick(),所有传给process.nextTick()的回调将在事件循环继续之前解析。这就会造成一些糟糕的情况,因为它允许你通过递归调用process.nextTick()来“饿死”你的I/O,阻止事件循环到达poll阶段。
为什么允许这样?
为什么Node.js中包含了这种玩意儿?部分原因是Node.js的设计理念,一个API应该总是异步的,即使不需要是异步。以下面的代码为例:
1 | function apiCall(arg, callback) { |
上面的代码做了一个参数检查,如果不正确,它会把错误传递到回调。最近对API进行了更新,允许传递参数给process.nextTick(),回调函数之后可以接收任意参数,这些参数会传给回调函数作为参数,这样就不必嵌套函数了。
我们做的是,在允许用户的剩余代码执行后,把错误传回给用户。通过使用process.nextTick(),我们保证了apiCall()总是在用户的剩余代码之后,事件循环继续之前 执行它的回调函数。为了实现这个,JS的调用栈允许栈展开然后立即执行提供的回调,该回调允许递归调用process.nextTick()而不会造成RangeError: Maximum call stack size exceeded from V8.
这种理念可能导致一些潜在的问题情况。如下例子:
1 | let bar; |
用户定义了someAsyncApiCall() ,为异步签名,但是实际上是同步地操作。当调用时,提供给someAsyncApiCall()的回调在事件循环的同意阶段调用了,因为someAsyncApiCall()实际上并没有做任何异步的操作。结果就是,回调试图引用bar,即使在作用域中可能没有该变量,因为代码未能运行完成。
通过将代码放入process.nextTick(),代码就有能力运行完成了,允许所有的变量、函数等等,在回调函数被调用之前先初始化。这还有个优势:不允许事件循环继续。对于用户来说,在事件循环继续之前,提醒错误可能有帮助。这是使用process.nextTick()后的代码:
1 | let bar; |
现实中的另一个例子:
1 | const server = net.createServer(() => {}).listen(8080); |
当只传递一个端口时,该端口立即被绑定。所以,'listening'回调可能立即被调用,问题在于那时.on('listening') 回调可能还没有设置。
为了避免这个问题,'listening'事件入队到nextTick(),来允许脚本运行到完成。这就允许用户去设置任何他们想要的事件处理器。
process.nextTick() VS setImmediate()
我们有两个相似的调用,但是它们的名字很让人困惑。
process.nextTick()在同一阶段立即触发setImmediate()在事件循环之后的迭代或’tick’触发
本质上,名称应该交换一下。process.nextTick() 比 setImmediate()触发的更快,但这是历史遗留问题,不可能改变。做这个转换会破坏npm上的大部分packages.每天都有新的模块添加,意味着我们每等一天,更多的潜在破坏会发生。虽然让门令人困惑,到那时名称本身不会变。
我们推荐开发者在所有情况下都使用
setImmediate(),因为更容易理解。
为什么使用process.nextTick()?
有两个重要的原因:
- 允许用户处理错误,清除任何不需要的资源,或者在事件循环继续之前再次尝试请求
- 当需要在调用栈展开之后但是事件循环继续之前运行回调时
一个例子就是匹配用户的期望。相似的例子:
1 | const server = net.createServer(); |
假设listen()在事件循环的开始处运行,但是listening回调放在setImmediate()中。除非传递了主机名,否则绑定到端口会立即发生。因为事件循环要继续,必定进入poll阶段,这意味着在listening事件之前,有机会接收到连接,触发connection事件。
另一个例子是,扩展EventEmitter并在constructor中触发一个事件:
1 | const EventEmitter = require('events'); |
你不可能在constructor立即触发一个事件,因为脚本还没处理到用户赋值回调给那个事件的地方。所以,在constructor,你可以使用process.nextTick()来设置一个回调,在constructor完成之后触发该事件。结果如预期:
1 | const EventEmitter = require('events'); |